
One problem that I’ve assigned when discussing Markov chains is to calculate the expected number of flips required for a particular pattern to appear. (Here I mean a pattern such as heads, heads, heads, or HHH.) In this post I’m going to discuss another approach – one that doesn’t use Markov chains – to solve this problem.
Suppose we want to find the expected number of flips required for the pattern HHH to appear. Call this X. We can calculate X by conditioning on the various patterns we might achieve that do or don’t give us HHH. For example, for our first few flips we could observe T, HT, HHT, or HHH. These cover the entire outcome space and have probability 1/2, 1/4, 1/8, and 1/8, respectively.
- If we observe T, then we effectively have to start the entire process over, and we’ve used one flip to get to that point. So, if we observe T, then the average number of flips required is
.
- If we observe HT, then we also have to start the entire process over, and we’ve used two flips to get there. For this outcome, the average number of flips required is
.
- If we observe HHT, then we have to start the entire process over, and we’ve used three flips. The average number of flips required for this scenario is
.
- Finally, if we observe HHH, then we have achieved our goal. The number of flips required is 3.
All together, then, the average number of flips required satisfies the equation

Solving for X, we obtain 
What if we have a more complicated pattern, though? Let’s look at HHT as an example. Let X be the expected number of flips required for HHT to appear for the first time.
Once again, we can condition on the various patterns we might achieve that do or don’t give us HHT. These are T, HT, HHH, and HHT. As in the previous example, these cover the entire outcome space and have probability 1/2, 1/4, 1/8, and 1/8, respectively.
- If we observe T, then we have to start over. The average number of flips required is
- If we observe HT, then we have to start over. The average number of flips required is
- If we observe HHH, then we don’t have to start over. It’s entirely possible that the HH at the end of HHH could be followed by a T, and then we would have achieved our pattern! Mathematically, this means that things get a bit more complicated.
- Let
denote the expected number of flips required for HHT to appear given that we currently have HH.
- Thus if we start with HHH, then the average number of flips required to obtain HHT is
.
- Now we need to determine
- If we currently have HH, then the next flip is either a T, which completes our pattern, or an H, we means we must start over in our quest to complete HHT given that we currently have HH.
- Thus
.
- Solving this yields
.
- Thus if we observe HHH, then the average number of flips required to obtain HHT is 3 + 2 = 5.
- Let
- Finally, if we observe HHT, then we have achieved our goal in 3 flips.
Therefore, 

Notice that it takes fewer flips, on average, to achieve HHT than it does HHH. This is because we don’t always have to start over every time the sequence fails to match our goal sequence.
The interested reader is invited to find the expected number of flips for the other sequences.

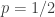 is null recurrent.)
is null recurrent.) .
.
 .
. 
![\displaystyle -\sqrt{1-4x} = -(1-4x)^{1/2} = -\sum_{k=0}^{\infty} \binom{1/2}{k} (-4x)^k \\ = -\sum_{k=0}^{\infty} \frac{-1}{2k-1} \binom{-1/2}{k} (-4x)^k, \text{ by Lemma 1} \\ = \sum_{k=0}^{\infty} \frac{1}{2k-1} \left(\frac{-1}{4}\right)^k \binom{2k}{k} (-4x)^k, \text{ by Identity 30 in [1]} \\ = \sum_{k=0}^{\infty} \frac{1}{2k-1} \binom{2k}{k} x^k.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++-%5Csqrt%7B1-4x%7D+%3D+-%281-4x%29%5E%7B1%2F2%7D+%3D+-%5Csum_%7Bk%3D0%7D%5E%7B%5Cinfty%7D+%5Cbinom%7B1%2F2%7D%7Bk%7D+%28-4x%29%5Ek+%5C%5C+%3D+-%5Csum_%7Bk%3D0%7D%5E%7B%5Cinfty%7D+%5Cfrac%7B-1%7D%7B2k-1%7D+%5Cbinom%7B-1%2F2%7D%7Bk%7D+%28-4x%29%5Ek%2C+%5Ctext%7B+by+Lemma+1%7D+%5C%5C+%3D+%5Csum_%7Bk%3D0%7D%5E%7B%5Cinfty%7D+%5Cfrac%7B1%7D%7B2k-1%7D+%5Cleft%28%5Cfrac%7B-1%7D%7B4%7D%5Cright%29%5Ek+%5Cbinom%7B2k%7D%7Bk%7D+%28-4x%29%5Ek%2C+%5Ctext%7B+by+Identity+30+in+%5B1%5D%7D+%5C%5C+%3D+%5Csum_%7Bk%3D0%7D%5E%7B%5Cinfty%7D+%5Cfrac%7B1%7D%7B2k-1%7D+%5Cbinom%7B2k%7D%7Bk%7D+x%5Ek.&bg=ffffff&fg=333333&s=0&c=20201002)
 , and let
, and let  . Since the generating function for
. Since the generating function for  is
is  (Lemma 2), and the generating function for
(Lemma 2), and the generating function for  is
is  (Identity 150 in [1]), the generating function for their convolution,
(Identity 150 in [1]), the generating function for their convolution, 

 just generates the sequence
just generates the sequence  , this means that
, this means that
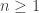 , we have
, we have
 , that we can make k cents’ worth of postage using only 4-cent and 5-cent stamps. But regular induction fails at the induction step: To prove that you can make
, that we can make k cents’ worth of postage using only 4-cent and 5-cent stamps. But regular induction fails at the induction step: To prove that you can make 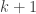 cents using only 4-cent and 5-cent stamps, knowing that you can make k cents isn’t helpful, since you can’t add either a 4-cent or a 5-cent stamp to k cents’ worth of postage to generate
cents using only 4-cent and 5-cent stamps, knowing that you can make k cents isn’t helpful, since you can’t add either a 4-cent or a 5-cent stamp to k cents’ worth of postage to generate 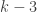 cents’ worth of postage. Then you can add a 4-cent stamp to that amount to produce your
cents’ worth of postage. Then you can add a 4-cent stamp to that amount to produce your  cents. And that’s the essence of strong induction.
cents. And that’s the essence of strong induction. (at least the ones I’ve seen) assume more math background than he has. So I tried another couple of arguments, and they seemed to convince him.
(at least the ones I’ve seen) assume more math background than he has. So I tried another couple of arguments, and they seemed to convince him. . Subtracting the first equation from the second leaves us
. Subtracting the first equation from the second leaves us  , which implies that
, which implies that  . Thus
. Thus  .
. and
and 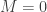 . This yields
. This yields .
. counterclockwise around the curve C. The boundary curve for a polygon consists of a finite set of line segments, though, and so to obtain our formula we just need to find out what
counterclockwise around the curve C. The boundary curve for a polygon consists of a finite set of line segments, though, and so to obtain our formula we just need to find out what  is for a line segment L that runs from a generic point
is for a line segment L that runs from a generic point 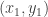 to another generic point
to another generic point  . Let’s do that now.
. Let’s do that now. from the starting point to the ending point work well, giving us the parameterization
from the starting point to the ending point work well, giving us the parameterization
 and
and  , we have
, we have  . This gives us the integral
. This gives us the integral![\displaystyle \int_0^1 (x_1 + t(x_2-x_1))(y_2-y_1)dt \\ = (y_2-y_1)\int_0^1 (x_1 + t(x_2-x_1))dt \\ = (y_2-y_1)\left[tx_1 + \frac{t^2}{2}(x_2-x_1)\right]_0^1 \\ = (y_2-y_1)\frac{x_1+x_2}{2}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cint_0%5E1+%28x_1+%2B+t%28x_2-x_1%29%29%28y_2-y_1%29dt+%5C%5C+%3D+%28y_2-y_1%29%5Cint_0%5E1+%28x_1+%2B+t%28x_2-x_1%29%29dt+%5C%5C+%3D+%28y_2-y_1%29%5Cleft%5Btx_1%C2%A0+%2B+%5Cfrac%7Bt%5E2%7D%7B2%7D%28x_2-x_1%29%5Cright%5D_0%5E1+%5C%5C+%3D+%28y_2-y_1%29%5Cfrac%7Bx_1%2Bx_2%7D%7B2%7D.&bg=ffffff&fg=333333&s=0&c=20201002)
 the difference in the y coordinates times the average of the x coordinates.
the difference in the y coordinates times the average of the x coordinates. , and so forth, until you label the last vertex
, and so forth, until you label the last vertex 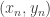 . Finally, give the starting vertex a second label of
. Finally, give the starting vertex a second label of  . Then the area of D is given by
. Then the area of D is given by
 .
.




 and
and  .
.



 , where i is a value between 0 and 4. As the angle measure increases from 0 radians to
, where i is a value between 0 and 4. As the angle measure increases from 0 radians to 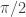 radians, the cosine value decreases from
radians, the cosine value decreases from  down to
down to  , while the sine value increases from
, while the sine value increases from  .
. . Thus we have
. Thus we have , recalling that
, recalling that  .
. ways to choose the people to be on the committee. Then there are k ways to choose the chair. Summing up over all possible values of k, we find that the answer is
ways to choose the people to be on the committee. Then there are k ways to choose the chair. Summing up over all possible values of k, we find that the answer is  .
. people, we have two options: Each person could be on the committee or not. Thus there are
people, we have two options: Each person could be on the committee or not. Thus there are 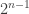 ways to choose the committee once the chair is chosen. This gives an answer of
ways to choose the committee once the chair is chosen. This gives an answer of  when choosing the chair first.
when choosing the chair first. , with respect to x to obtain
, with respect to x to obtain  . Letting
. Letting  , and the probability that the remaining flips are all tails is
, and the probability that the remaining flips are all tails is  . Multiply these together and apply the definition of expected value to get an answer of
. Multiply these together and apply the definition of expected value to get an answer of  .
.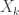 be
be  if flip k is heads and
if flip k is heads and  if flip k is tails. Then the number of heads in the sequence of n flips is
if flip k is tails. Then the number of heads in the sequence of n flips is  . Also, the expected value of
. Also, the expected value of  . Thus the expected number of heads is
. Thus the expected number of heads is  . (This is a formal way of arguing for the answer of
. (This is a formal way of arguing for the answer of  that our intuition says should be the expected number of heads.)
that our intuition says should be the expected number of heads.) , which implies
, which implies  and
and 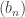 is given by
is given by  .
. and
and  then
then  . (This is the binomial convolution property for exponential generating functions.)
. (This is the binomial convolution property for exponential generating functions.) . (This is the Maclaurin series for
. (This is the Maclaurin series for 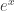 .)
.) is the exponential generating function for the sequence given by
is the exponential generating function for the sequence given by  .
. and
and  . What are the exponential generating functions of these two sequences?
. What are the exponential generating functions of these two sequences?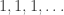 , append a
, append a  .
. . However,
. However,  , which means that
, which means that  is the exponential generating function for the sequence
is the exponential generating function for the sequence  . Thus, by Property 3,
. Thus, by Property 3,  is also the exponential generating function for the sequence
is also the exponential generating function for the sequence  . Since
. Since  and
and  have the same generating function, they must be equal, and so
have the same generating function, they must be equal, and so  for each
for each  . If
. If  and
and  then, for
then, for 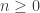 ,
, 
 , then
, then  . Thus
. Thus  , and, by the theorem,
, and, by the theorem,  .
. , then
, then  . By the theorem and the previous result, then,
. By the theorem and the previous result, then,  .
. is a concise way to represent the alternating harmonic series and its value, but it’s also a foreign language to the vast majority of players out there. As such, when the typical player encounters something like this expression in a game it is not inviting or engaging. Instead, it’s intimidating and off-putting. As game designers it is our responsibility to find ways to express fascinating mathematical ideas without triggering players’ phobias around mathematics, many of which are (I’m convinced) tied to those ideas’ symbolic representations. For example, when I gave my talk at NarraScope I displayed the alternating harmonic series equation above as an example of something to avoid. Then I demoed a couple of puzzles from A Beauty Cold and Austere, the second of which was the sequences-and-series machine. After playing with several of the settings to see what happened I picked a particular collection of settings and asked the audience whether we could predict where the golden path would lead. We agreed that these settings would not get us to infinity (unlike another setting) nor result in values that bounced around more and more wildly (also unlike another setting). Instead, these settings would create a path that would eventually settle down to a limiting value somewhere between 0 and 1. And sure enough, that’s what happened, with the game telling us that the actual value was the natural logarithm of 2. Then I pointed out that we had just recreated the ideas behind the alternating harmonic series equation I had displayed fifteen minutes earlier, without using any mathematical symbols at all. That produced multiple murmurs from the audience, including a “mind blown” comment from someone sitting near the front. (I’ll admit that that was my favorite moment of the whole talk.) The point is that we can avoid symbolic manipulation when representing mathematics in games, even if we have to get creative in how we do it.
is a concise way to represent the alternating harmonic series and its value, but it’s also a foreign language to the vast majority of players out there. As such, when the typical player encounters something like this expression in a game it is not inviting or engaging. Instead, it’s intimidating and off-putting. As game designers it is our responsibility to find ways to express fascinating mathematical ideas without triggering players’ phobias around mathematics, many of which are (I’m convinced) tied to those ideas’ symbolic representations. For example, when I gave my talk at NarraScope I displayed the alternating harmonic series equation above as an example of something to avoid. Then I demoed a couple of puzzles from A Beauty Cold and Austere, the second of which was the sequences-and-series machine. After playing with several of the settings to see what happened I picked a particular collection of settings and asked the audience whether we could predict where the golden path would lead. We agreed that these settings would not get us to infinity (unlike another setting) nor result in values that bounced around more and more wildly (also unlike another setting). Instead, these settings would create a path that would eventually settle down to a limiting value somewhere between 0 and 1. And sure enough, that’s what happened, with the game telling us that the actual value was the natural logarithm of 2. Then I pointed out that we had just recreated the ideas behind the alternating harmonic series equation I had displayed fifteen minutes earlier, without using any mathematical symbols at all. That produced multiple murmurs from the audience, including a “mind blown” comment from someone sitting near the front. (I’ll admit that that was my favorite moment of the whole talk.) The point is that we can avoid symbolic manipulation when representing mathematics in games, even if we have to get creative in how we do it.